|
Strategies for Whole Genome Sequencing
map-based
sequencing - which sequences mapped fragments (1000kb)
shotgun
sequencing - which sequences random fragments (500kb)
1. genome is cut into 160Kb fragments
2. fragments inserted into
BAC*g -
bacterial
artificial chromosomes
Yeast
artificial chromosomes
3.
BAC
segments are cut in 1000bp pieces
4. 1K pieces are put into plasmids & plasmids copied
5. copies are sequenced
6.
pieces are
overlapped in sequence creating the entire 160KB sequenced
Understanding the genome
sequence
the
genome sequence is like a parts list or dictionary, except that it has no
punctuation "doormotorwheeltirewindowradiatorfendernutbolt"
one needs to
annotate the sequence by finding gene (coding
segments),
called Open Reading Frames (ORF's)
in prokaryote:
look for start (5'ATG'3) and stop (5'TGA'3) codons. Computers
can also search for promoters, operators, regulators.
in eukaryotes: introns & exons present a problem; known sequences of cDNA
probes can be used by computers to spot ORF's.
Open reading frames: once found one can check sequence against catalogs of known
genes.
Problems
in Sequences eukaryotic genomes...
1.
size:
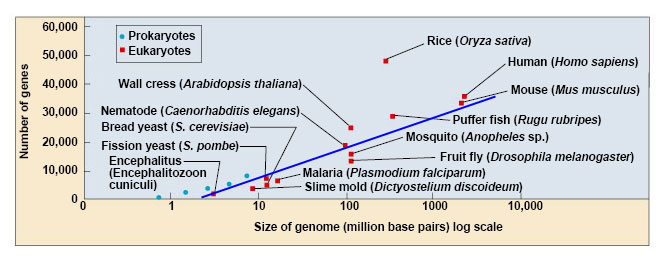
Humans contain up to
2,000 more DNA bp's than other organisms (table)
Human genome expected to have 100,000+ genes, but only has
30,000?
if proc's have a strong correlation between genome size, gene number,
and metabolic capability (# proteins), why don't eukaryotes?
alternative
splicing - on average each coding eucaryotic locus
produces 3 distinct mRNA transcripts = 120,000 proteins?
2.
repeat sequences: > 50% human DNA is repeat
sequences
a. most is due to transposable elements - segments capable of moving
from one location to another in a genome.
LINE elements - long interspersed nuclear elements,
which hold
a promoter and 2 genes (a reverse transcriptase & an integrase)
b. simple repeat sequences: makes up 3% of human genome
microsatellites - stretches of 1 to 13 bp - mostly
dinucleotide ...ACACAC...
minisatellites - repeat units of 14 to 500 bp's
locations of satellites in chromosomes are highly variable from individual to
individual
during replication repeat satellites
misalign at
synapse and DNA polymerase slips
result is every individual has a UNIQUE number of repeats at satellite loci,
which becomes the basis of DNA fingerprinting.
3.
split genes: in humans only 5% of DNA is
exons
What
have we learned of bacterial
& archaeal
genomes to date (summer 2002)
1. there is a general correlation between
SIZE of genome & metabolic
capability
parasites have small genomes and require host metabolism (Mycoplasms)
non-parasites have large genomes (E. coli &
Pseudomonas 10x larger)
2. many sequenced genes have NO known function
38% of E. coli genome's use is unknown
3. about 15% of each prokaryotic genome is unique
to that species
4. redundancy of sequence is very common
E. coli has 86 gene pairs that are identical (diploidy?)
5. more than one chromosome in proc's is common
many prokaryotes has 2 circular DNA molecules
6. most prokaryotes have plasmids
7. many prokaryotes are scavengers by acquiring DNA
from other species
done via Lateral Transfer, i.e.,
a) proc's take up raw pieces of DNA from environment
b) Chlamydia bacteria (cause STD's) contain may euc-like
genes
c) pathogenic E.coli have 1,400 or more genes than non-pathogens,
that are similar to gene sequences from phage viruses, thus
"prokaryotic pathogenic genes may have a viral origin".
Gene Families
- groups of genes clustered along the same chromosome
probably arose from a common ancestral gene sequence through gene duplication
especially via unequal crossing over.
a Pseudogene - a DNA sequence that closely
resembles a working gene,
but is not transcribed, & has no known function.
back
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}